









Évaluer la qualité des résumés juridiques générés par l’IA avec EVA
Le défi des résumés juridiques
Les décisions de justice sont longues, complexes et denses en références. Les résumer de manière fiable avec l’IA est un défi :
- un détail omis peut changer l’interprétation du texte,
- une mauvaise citation d’article de loi peut induire en erreur,
- même les modèles avancés (ChatGPT, Copilot de Microsoft, Qwen3, Lexis+AI…) produisent parfois des résumés incomplets ou inexacts.
C’est pourquoi il ne suffit pas de générer un résumé : il faut aussi l’évaluer objectivement.
Les risques d’un résumé erroné
- Erreurs factuelles : un chiffre ou un article modifié peut fausser l’analyse.
- Perte de temps : relire et corriger chaque résumé annule le gain de productivité.
- Risques juridiques : une erreur dans un document peut avoir des conséquences sérieuses.
Ces risques montrent la nécessité d’un outil d’évaluation automatisée, rigoureux et transparent.
L’expérimentation
Pour tester la fiabilité des résumés générés par l’IA, j’ai mené une expérimentation en plusieurs étapes :
Sélection des sources
- J’ai utilisé de vraies décisions de justice comme textes de référence.
Génération des résumés
- J’ai demandé à différents modèles (ChatGPT, Copilot de Microsoft, Qwen3) de produire chacun un résumé du même texte.
- Chaque résumé avait son style et ses limites : certains trop longs, d’autres incomplets, ou encore imprécis sur les citations légales.
Évaluation avec EVA : disponible ici : https://lexiorgpt-eva.streamlit.app/:
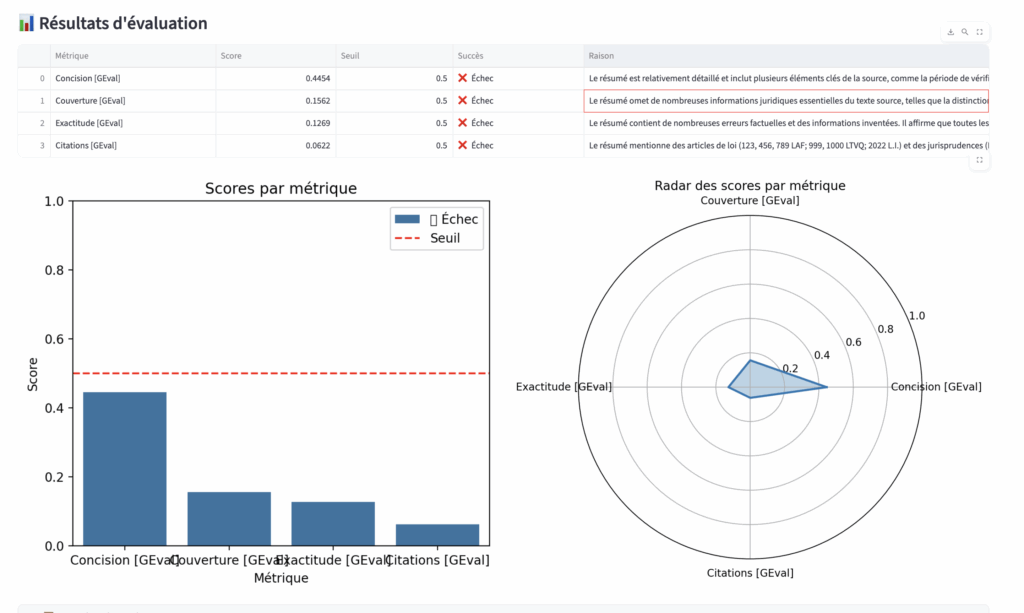
Grâce à EVA (Évaluation des résumés automatisée), basé sur le framework DeepEval, j’ai évalué chaque résumé selon quatre métriques :
- Concision : va-t-il à l’essentiel ?
- Couverture : contient-il les points clés ?
- Exactitude : reflète-t-il fidèlement le texte source ?
- Citations : les références sont-elles correctement reproduites ?
EVA fournit à la fois un score et des commentaires détaillés (graphiques + feedback qualitatif).
Amélioration guidée
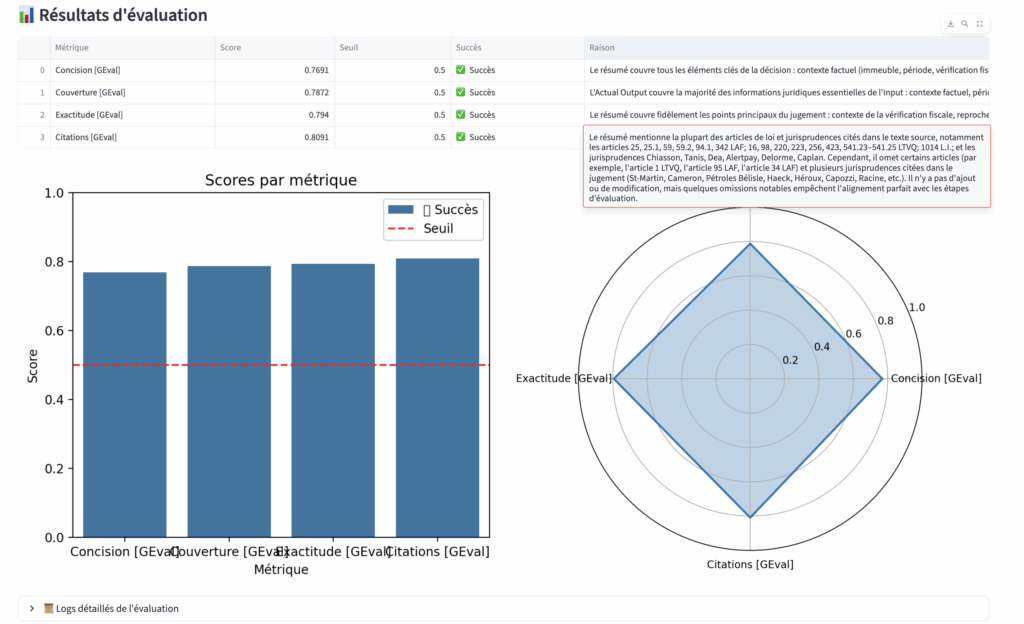
- En utilisant les commentaires générés par l’évaluation, j’ai réinjecté ces retours dans un nouveau prompt.
- Les modèles ont ainsi corrigé leurs propres résumés pour atteindre une précision optimale.
Tests de robustesse
- J’ai volontairement introduit des erreurs (ex. changer un chiffre d’article de loi) pour vérifier si l’outil les détectait.
- Résultat : même ces erreurs subtiles ont été repérées.
Résultats : vers un résumé auto-correctif
Cette expérimentation montre deux points essentiels :
- L’évaluation améliore la qualité : en exploitant les retours d’EVA, les résumés deviennent progressivement plus fiables et complets.
- Vers un système multi-agent : cette boucle (résumé → évaluation → correction → nouveau résumé) ouvre la voie à un futur outil de résumé juridique multi-agent, capable de :
- générer un résumé,
- s’auto-corriger à partir de ses propres erreurs,
- afficher en toute transparence ses scores et justifications.
Un tel outil renforcerait non seulement la confiance dans l’IA, mais aussi la traçabilité et la transparence du processus de résumé.
Conclusion
Les modèles d’IA seuls ne suffisent pas : ils produisent encore trop souvent des résumés approximatifs.
En revanche, lorsqu’ils sont associés à un système d’évaluation automatisée comme EVA, ils deviennent capables de s’améliorer par itération.
L’avenir du résumé juridique réside dans des outils intelligents, multi-agents, transparents et fiables, capables de combiner génération, évaluation et correction continue.


