









Choix des métriques pour l’évaluation des modèles de langage (LLM)
L’évaluation des modèles de langage (LLM) repose sur des métriques spécifiques qui permettent de quantifier les performances des systèmes LLM. Ces métriques, telles que la pertinence des réponses, la similarité sémantique et la détection des hallucinations, sont cruciales pour évaluer la qualité des sorties des LLM en fonction de critères prédéfinis. Cet article explore les différentes métriques d’évaluation des LLM et leur importance dans le cadre de la mise en production des systèmes LLM.
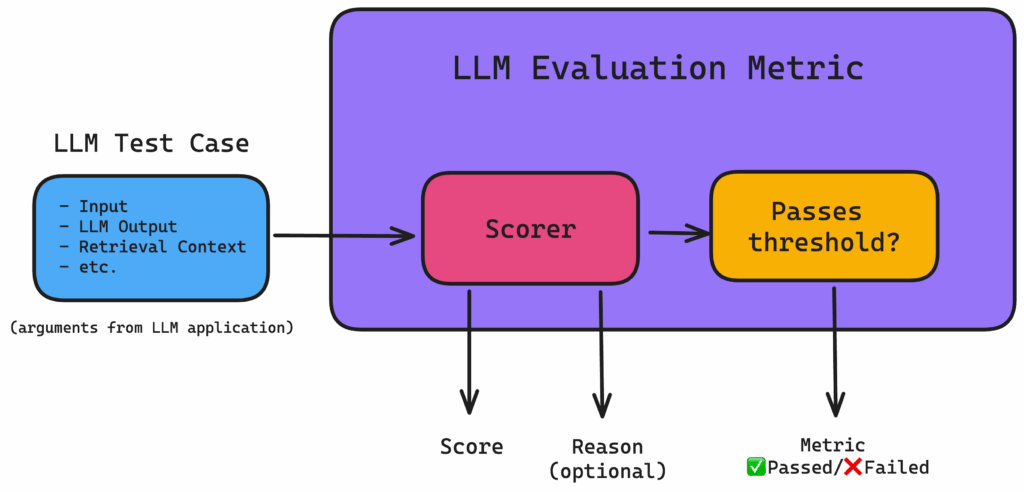
Architecture des métriques d’évaluation des LLM
Les métriques d’évaluation des LLM peuvent être classées en deux grandes catégories :
- les évaluateurs statistiques
- les évaluateurs basés sur des modèles.
Chaque catégorie présente des avantages et des inconvénients en fonction des besoins spécifiques de l’évaluation.
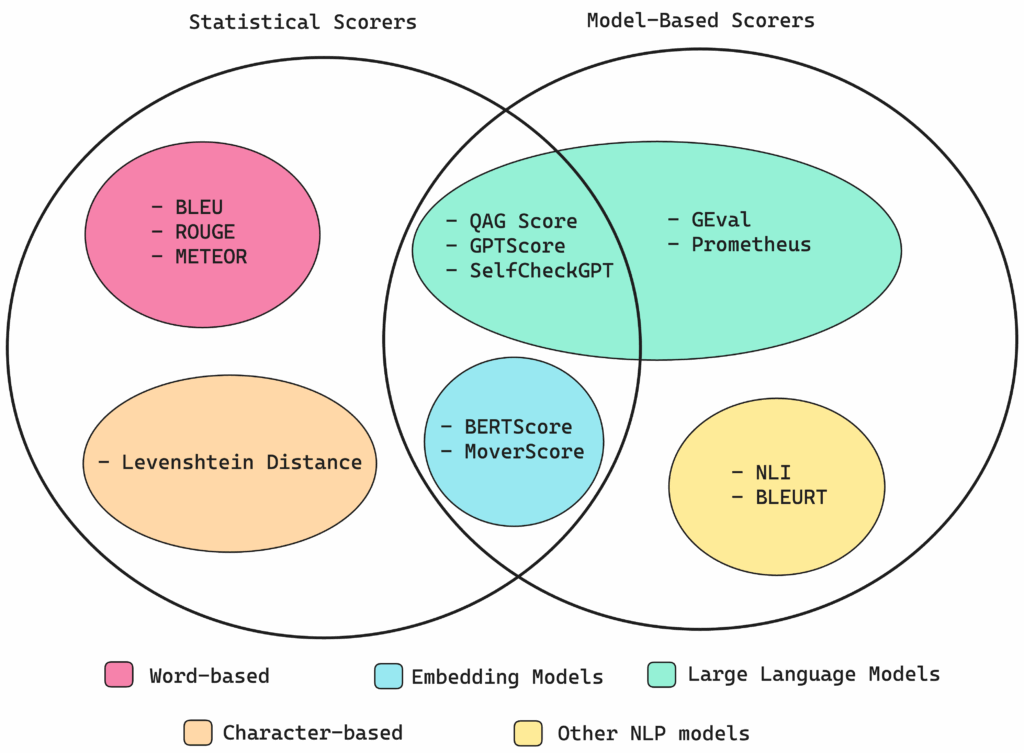
Évaluateurs statistiques
Les méthodes statistiques sont souvent utilisées pour des évaluations rapides et simples, bien qu’elles soient limitées lorsqu’un raisonnement complexe est requis.
Parmi les principales méthodes statistiques, on trouve :
- BLEU (BiLingual Evaluation Understudy) : Cette métrique évalue la précision des sorties LLM en comparant les n-grammes des sorties avec ceux des vérités terrain annotées. La moyenne géométrique des précisions est calculée, avec une pénalité de brièveté appliquée si nécessaire.
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation) : Utilisée principalement pour l’évaluation des résumés de texte, cette métrique calcule le rappel en mesurant le chevauchement des n-grammes entre les sorties LLM et les références.
- METEOR (Metric for Evaluation of Translation with Explicit Ordering) : Plus complète, cette métrique évalue à la fois la précision et le rappel, ajustés pour les différences d’ordre des mots, et utilise des bases de données linguistiques comme WordNet pour tenir compte des synonymes.
- Distance de Levenshtein : Cette métrique calcule le nombre minimum de modifications de caractères nécessaires pour transformer une chaîne de texte en une autre, utile pour des tâches nécessitant un alignement précis des caractères.
Évaluateurs basés sur des modèles
Les évaluateurs basés sur des modèles NLP offrent une précision accrue en prenant en compte la sémantique, mais leur nature probabiliste peut introduire une certaine variabilité dans les scores.
Parmi ces méthodes, on trouve :
- NLI (Natural Language Inference) : Utilisant des modèles d’inférence de langage naturel, cette métrique classe les sorties LLM comme logiquement cohérentes, contradictoires ou sans rapport par rapport à un texte de référence.
- BLEURT (Bilingual Evaluation Understudy with Representations from Transformers) : Cette métrique utilise des modèles pré-entraînés comme BERT pour évaluer les sorties LLM par rapport à des sorties attendues.
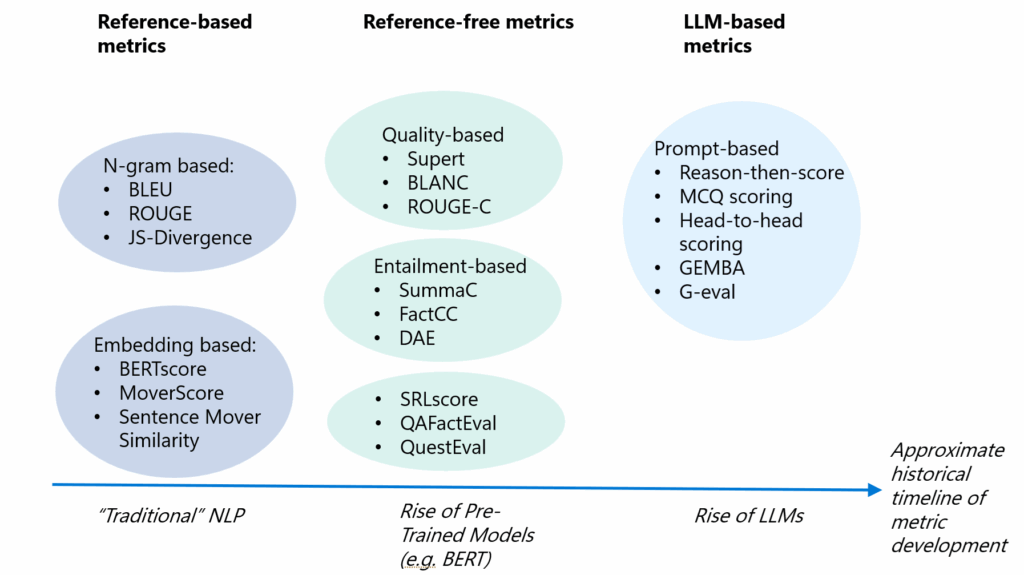
Métriques d’évaluation spécifiques aux LLM
Les métriques d’évaluation des LLM incluent des critères tels que la pertinence des réponses, l’exactitude, la détection des hallucinations, la pertinence contextuelle, les métriques responsables et les métriques spécifiques à la tâche. Ces métriques sont essentielles pour évaluer les performances des systèmes LLM dans des contextes variés.
- Pertinence des réponses : Évalue si la sortie d’un LLM répond de manière informative et concise à l’entrée donnée.
- Exactitude : Vérifie si la sortie d’un LLM est factuellement correcte par rapport à une vérité terrain.
- Hallucination : Détecte la présence d’informations fausses ou inventées dans la sortie d’un LLM.
- Pertinence contextuelle : Évalue la capacité du récupérateur dans un système LLM basé sur RAG à extraire les informations les plus pertinentes pour le LLM.
- Métriques responsables : Inclut des critères tels que le biais et la toxicité pour déterminer si la sortie d’un LLM contient du contenu potentiellement nuisible ou offensant.
- Métriques spécifiques à la tâche : Inclut des critères personnalisés en fonction du cas d’utilisation, tels que la synthèse pour les résumés d’articles de presse.
Une bonne évaluation d’un LLM ne se limite pas à une seule métrique. C’est un mélange :
- des mesures statistiques pour la rapidité,
- des évaluations basées sur des modèles pour la profondeur,
- et des critères adaptés au cas d’usage pour rester pertinent.
En combinant ces approches, on obtient une vision complète de la performance du LLM et on maximise les chances de succès lors de sa mise en production.


